شرح خوارزمية BiDi: كيف يعرض الكمبيوتر النصوص العربية؟
ما هي خوارزمية BiDi وكيف تعمل؟
عندما نكتب نصًا عربيًا يحتوي على كلمات إنجليزية أو أرقام، قد يظهر أحيانًا بترتيب غير متوقع. السبب ليس أن الكمبيوتر “يفهم العربية” أو “يفهم الإنجليزية” كما نفهمها نحن، بل لأنه يتعامل أولًا مع بايتات، ثم مع ترميزات مثل Unicode و UTF-8، وأخيرًا مع خوارزمية العرض BiDi.
في هذه المقالة سنمر على الطريق كاملًا: كيف تُخزن الحروف داخل الذاكرة، وكيف يحصل كل حرف أو رمز على رقمه الخاص، ثم كيف يقرر النظام ترتيب عرض النص عندما يجتمع العربي والإنجليزي في السطر نفسه.
1. كيف تُخزن النصوص داخل الكمبيوتر؟
الكمبيوتر لا يفهم الحروف أو الصور بالشكل الذي نراه نحن. في النهاية هو يتعامل مع أصفار وآحاد فقط: 0 و1. وأصغر وحدة هنا هي البت (bit)، أما البايت (byte) فيتكون من 8 بتات.
لذلك فالنص داخل الكمبيوتر لا يُخزن على شكل “حروف”، بل على شكل سلسلة من البايتات.
2. البداية: ASCII
في ستينيات القرن الماضي ظهر نظام ASCII، وكان يُخصِص رقمًا لكل حرف إنجليزي أو رمز شائع. مثلًا:
- الحرف
Aرقمه65 - الحرف
aرقمه97
كان هذا النظام مناسبًا للإنجليزية، لكنه محدود جدًا لأنه لا يغطي إلا عددًا صغيرًا من الحروف والرموز. لذلك لم يكن كافيًا للغات مثل العربية، والصينية، واليابانية.
3. الحل الأشمل: Unicode
ظهر Unicode لحل هذه المشكلة. فكرته بسيطة: إعطاء كل حرف في كل لغة رقمًا فريدًا يسمى Code Point.
أمثلة:
- الحرف
أله الرقمU+0623 - الحرف
بله الرقمU+0628 - الإيموجي
😊له الرقمU+1F60A
لكن Unicode لا يجيب وحده عن سؤال: كيف نخزن هذه الأرقام فعليًا داخل الملف أو الذاكرة؟ هنا يأتي دور UTF-8.
4. كيف يعمل UTF-8؟
UTF-8 هو أشهر نظام لترميز النصوص في العالم اليوم. وظيفته هي تحويل أرقام Unicode إلى بايتات فعلية يمكن تخزينها ونقلها.
يمتاز UTF-8 بأنه مرن:
- 1 بايت: لمعظم محارف الإنجليزية الأساسية في ASCII
- 2 بايت: لكثير من الحروف مثل الحروف العربية الأساسية
- 3 أو 4 بايت: لمحارف أخرى أكثر تعقيدًا، مثل بعض الرموز والإيموجي
وهذا ما يجعله عمليًا: النصوص الإنجليزية لا تستهلك مساحة كبيرة، وفي الوقت نفسه يمكنه تمثيل أغلب لغات العالم.
لنأخذ مثالًا A س b داخل الكمبيوتر. قد يبدو التمثيل المبسط هكذا:
| 01000001 | 00100000 | 11011000 10110011 | 00100000 | 01100010 |
|---|---|---|---|---|
| A | مسافة | س | مسافة | b |
نلاحظ هنا أن الحرف العربي قد يحتاج إلى أكثر من بايت واحد، بخلاف الحروف الإنجليزية الأساسية في ASCII.
ملاحظة مهمة: الكمبيوتر لا يخزن معلومة تقول: “هذا المقطع يجب أن يُقرأ من اليمين إلى اليسار”. هو يخزن بايتات فقط. أما اتجاه العرض على الشاشة فيُعالَج لاحقًا، وهنا تظهر أهمية خوارزمية BiDi.
5. لماذا نحتاج خوارزمية BiDi؟
إذا كانت الجملة كلها عربية، فغالبًا لا توجد مشكلة واضحة. وإذا كانت كلها إنجليزية، فالأمر بسيط أيضًا. لكن التحدي يظهر عند خلط أكثر من اتجاه في السطر نفسه، مثل:
مرحبا hello 42في هذه الحالة لا يكفي أن نعرف الحروف فقط، بل نحتاج إلى قواعد تحدد كيف تُعرض هذه الحروف على الشاشة بالترتيب الصحيح. هذه هي مهمة خوارزمية BiDi، اختصارًا لـ Bidirectional Algorithm.
6. كيف تحدد BiDi اتجاه الفقرة؟
تعطي Unicode لكل حرف خاصية اتجاه تسمى Bidi Character Type. بعض الحروف تكون:
- R أو AL: لحروف تُعرض من اليمين إلى اليسار
- L: لحروف تُعرض من اليسار إلى اليمين
- EN: للأرقام الأوروبية
- WS: للمسافات
ثم تبحث الخوارزمية عن أول حرف قوي (strong character) خارج نطاق الـ Isolates لتحدد الاتجاه الأساسي للفقرة (P1، P2، P3). فإذا كان أول حرف قوي عربيًا، يصبح الاتجاه الأساسي RTL.

R => عربي L => لاتيني EN => رقم أوروبي WS => Whitespace

7. مستويات الاتجاه
بعد تحديد اتجاه الفقرة، تعطي الخوارزمية كل مقطع مستوى تضمين embedding level. الفكرة الأساسية هي:
- المستوى الزوجي يعني عرضًا من اليسار إلى اليمين
- المستوى الفردي يعني عرضًا من اليمين إلى اليسار
المستوى لا يصف “نوع الحرف” بقدر ما يصف موضعه داخل بنية النص واتجاهه أثناء العرض.

فكرة المستويات باختصار:
- رقم زوجي = LTR
- رقم فردي = RTL
- كلما دخلنا مقطعًا ذا اتجاه مختلف، قد يرتفع المستوى
- الحد الأقصى للمستويات هو 125
مثال على فقرة أساسية من اليسار إلى اليمين:
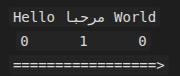
هنا يبدأ النص الإنجليزي من المستوى 0، وعندما يدخل مقطع عربي داخله قد يرتفع إلى المستوى 1.
ومثال على فقرة أساسية من اليمين إلى اليسار:
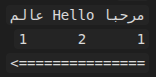
هنا يبدأ النص العربي من المستوى 1، وعندما يظهر مقطع إنجليزي داخله قد يرتفع إلى المستوى 2.
8. ماذا عن المسافات وعلامات الترقيم؟
ليست كل المحارف ذات اتجاه واضح. فالمسافات وبعض علامات الترقيم تعد محايدة، واتجاهها يتحدد بحسب السياق.
إذا كانت المسافة بين مقطعين من النوع نفسه، فإنها تميل إلى أخذ اتجاههما. أما إذا كانت بين مقطع عربي ومقطع إنجليزي مثلًا، فقد تأخذ اتجاه الفقرة الأساسي. لهذا تظهر المسافات أحيانًا في مكان يبدو غريبًا إذا لم نفهم قواعد BiDi.
القاعدتان الأساسيتان هنا هما N1 وN2: المحارف المحايدة قد تكتسب اتجاه ما يحيط بها، أو تعود إلى اتجاه الفقرة إذا اختلف السياق حولها.

9. ما هي الـ Runs؟
بعد حساب المستويات، تُقسَّم الجملة إلى مجموعات متجاورة لها المستوى نفسه. هذه المجموعات تسمى Runs.
لنأخذ الجملة التالية مثالًا:
مرحبا hello بكمقد تُقسم إلى عدة Runs متتالية، بعضها RTL وبعضها LTR، بحسب المستوى المحسوب لكل جزء.



10. إعادة ترتيب الـ Runs
بعد أن حسبت الخوارزمية المستويات وحددت الـ Runs، تأتي الخطوة الأخيرة: إعادة الترتيب لأجل العرض.
القاعدة العامة:
- نبدأ من مستوى الفقرة الأساسي.
- ننظر إلى المقاطع بحسب مستوياتها.
- المقاطع ذات المستوى الزوجي تُعرض بصريًا من اليسار إلى اليمين.
- المقاطع ذات المستوى الفردي تُعرض بصريًا من اليمين إلى اليسار.
- عند وجود تداخل، تبدأ المعالجة من المستويات الأعلى ثم الأدنى.
(Unicode UAX #9 — Reordering Resolved Levels)
مثال عملي
لنفرض أن لدينا النص التالي:
مرحبا hello بكمإذا كان مستوى الفقرة الأساسي هو 1، فقد يكون التقسيم المبسط هكذا:
مرحبا→ مستوى1→ RTLمسافة→ مستوى1→ RTLhello→ مستوى2→ LTRمسافة→ مستوى1→ RTLبكم→ مستوى1→ RTL
وبعد تطبيق قواعد إعادة الترتيب يظهر النص على الشاشة هكذا:
مرحبا hello بكم
لاحظ هنا:
- الكلمة الإنجليزية لم ينعكس ترتيب حروفها الداخلي لأنها ما زالت LTR
- المقاطع العربية عُرضت ضمن سياق RTL
- مواضع المسافات تأثرت بالمستوى والسياق المحيط بها
الخلاصة
لفهم النصوص المختلطة بالعربية والإنجليزية، من المفيد أن نفصل بين ثلاث طبقات مختلفة:
- Unicode: يعطي كل حرف رقمًا فريدًا.
- UTF-8: يحدد كيف يُخزن هذا الرقم على شكل بايتات.
- BiDi: يحدد كيف تُعرض هذه المحارف على الشاشة عندما تختلط الاتجاهات.
لذلك فالمشكلة ليست في “تخزين العربية” فقط، بل في الانتقال من التمثيل الرقمي إلى العرض البصري الصحيح. وحين نفهم هذا المسار، تصبح كثير من التصرفات الغريبة للنص المختلط منطقية ومفسَّرة.